4 Padrões de Engenharia de Dados para Marketing: Guia Essencial para Pipelines Confiáveis e Escaláveis


Como arquitetar pipelines mais confiáveis integrando dados de Analytics, CRM e outras fontes de marketing
O marketing sempre dependeu de dados. Mas a natureza dessa dependência mudou significativamente nos últimos anos, principalmente no marketing digital.
Durante muito tempo, bastava ter um bom relatório de campanha. Hoje, dados de comportamento sustentam desde a personalização em tempo real até modelos de atribuição multicanal e estratégias de fidelização. Ter um pipeline de dados confiável deixou de ser uma vantagem competitiva: é um pré-requisito para que o produto do negócio seja relevante para o cliente.
Parte dessa mudança é estrutural. Os clientes estão em mais lugares ao mesmo tempo: navegam no app, veem um anúncio no feed de uma rede social, visitam a loja física, pesquisam no Google e finalizam a compra pelo site. Cada ponto de contato gera dados. E as empresas, ao expandirem seus portfólios com novos produtos e os canais por meio dos quais esses produtos podem ser descobertos e explorados, amplificam continuamente esse volume.
Outra parte é tecnológica. A adoção de inteligência artificial no marketing acelerou a captura e o consumo de dados. Plataformas que gerenciam esses dados geram volumes massivos de eventos que precisam ser coletados, processados e transformados em métricas acionáveis.
O resultado são ambientes de dados cada vez mais complexos, com pipelines criados para resolver problemas imediatos que, sem uma arquitetura estruturada, acumulam dívida técnica ao longo do tempo.
Uma forma eficaz de lidar com essa complexidade é aplicar padrões de engenharia de dados. Assim como na engenharia de software, padrões descrevem soluções recorrentes para problemas comuns de arquitetura. Em vez de reinventar a roda a cada projeto, é possível aplicar abordagens consolidadas para ingestão, transformação, qualidade e observabilidade de dados.
O livro Data Engineering Design Patterns, de Bartosz Konieczny (O'Reilly, 2025), apresenta um catálogo abrangente dessas soluções. Este artigo explora quatro padrões especialmente relevantes para projetos de dados em marketing digital, ilustrando cada um com situações reais anonimizadas vivenciadas em projetos da DP6.
Padrão 1: Replicador de Dados
O problema
A maior parte dos dados de marketing reside em plataformas externas sobre as quais o time de dados não tem controle. Google Analytics, Meta Ads, Google Ads e plataformas de CRM: cada uma foi projetada para operação e relatórios básicos, não para análises complexas, integração entre sistemas ou armazenamento histórico de longo prazo.
Consultar essas plataformas diretamente durante análises pode trazer diversas limitações, como restrições de volume de requisições, uso de amostragem em datasets maiores, latência elevada e impossibilidade de cruzar dados entre fontes distintas.
Para construir análises integradas, cruzando comportamento de usuário, campanhas de mídia e dados de conversão, é necessário trazer esses dados para um ambiente centralizado.
O padrão
O Replicador de Dados consiste em copiar dados de sistemas operacionais externos para um ambiente analítico centralizado, geralmente um data lake ou data warehouse. O livro faz uma distinção importante entre replicação e carregamento de dados: enquanto o carregamento é mais flexível, a replicação tem como objetivo preservar os atributos de metadados da origem, como chaves primárias em bancos de dados ou posições de eventos em brokers de streaming.
Existem duas variações principais:
Passthrough Replicator (EL: Extract and Load)
Replica os dados sem transformações, preservando-os exatamente como chegam da origem. O objetivo é garantir fidelidade total aos dados brutos, permitindo auditoria e reprocessamento futuros.
Transformation Replicator (ETL: Extract, Transform and Load)
Aplica transformações durante a replicação, como normalização de campos, remoção de atributos sensíveis ou enriquecimento de registros.
Na prática, projetos de marketing combinam ambos. Os dados brutos são preservados em uma camada raw, e as transformações ocorrem em camadas subsequentes da arquitetura.
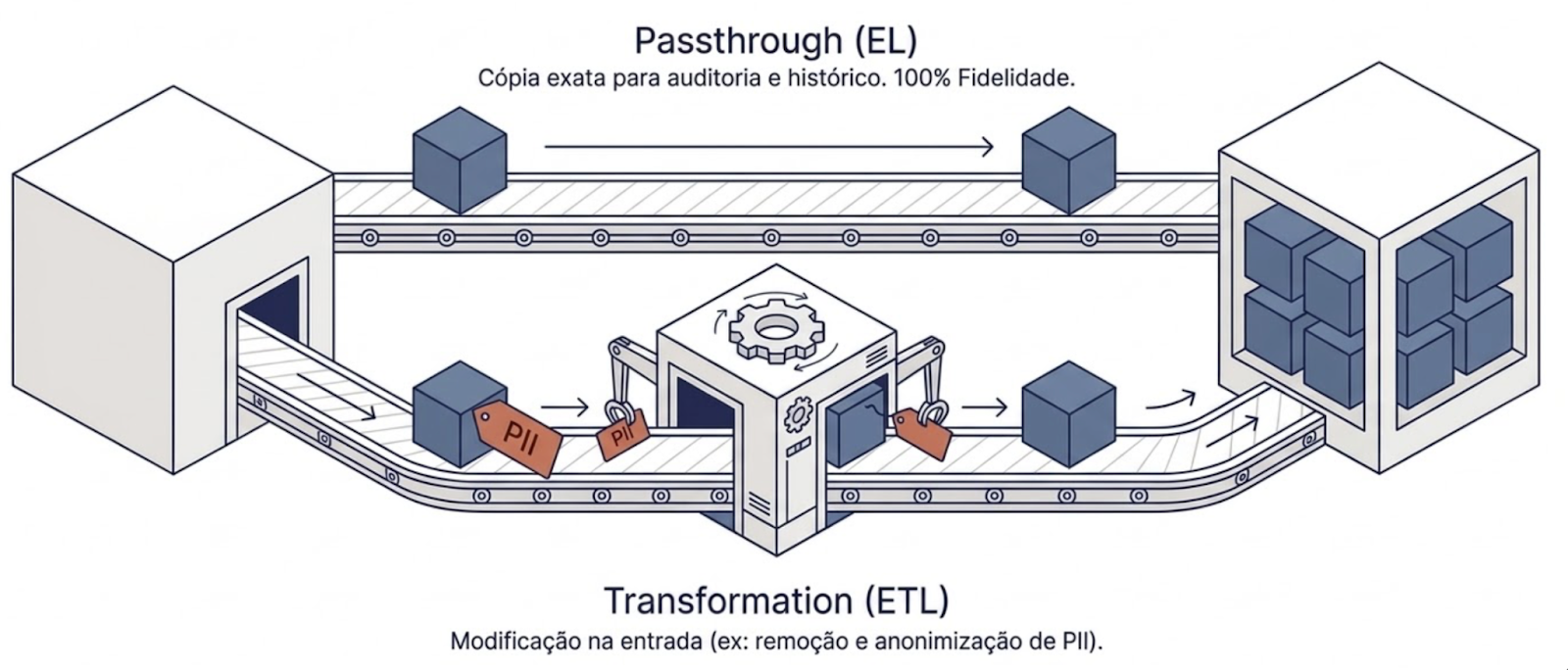
Esse padrão resolve três problemas de uma vez: elimina a dependência de fontes e APIs externas durante consultas analíticas, permite manter histórico completo dos dados e viabiliza integrações entre fontes distintas.
Replicação em arquiteturas multi-cloud
Um cenário em que o padrão Replicador aparece com frequência, especialmente em grandes organizações, é o de arquiteturas multi-cloud. Diferentes sistemas muitas vezes operam em provedores de nuvem distintos, e pipelines de replicação também são utilizados para mover dados entre esses ambientes, garantindo que todos os sistemas analíticos tenham acesso às mesmas informações.
Esse cenário pode ocorrer por diferentes motivos:
- Integração entre sistemas que utilizam provedores distintos
- Requisitos de governança e/ou compliance que impõem restrições sobre onde os dados podem residir
- Necessidade de centralizar dados em um único ambiente analítico
Uso de ferramentas analíticas específicas disponíveis em uma determinada plataforma
Nesse contexto, o Replicador não apenas integra dados de plataformas de marketing, mas também atua como mecanismo de sincronização entre diferentes ambientes de infraestrutura.
Como a DP6 aplica esse padrão no dia a dia?
Case 1: Democratização de dados de analytics em ambiente multi-cloud
Em um cliente do setor financeiro, os dados do Google Analytics eram exportados diariamente para o Google Cloud Platform (GCP). O data mesh corporativo da empresa, no entanto, operava na AWS. Na prática, isso fazia com que esses dados não estivessem acessíveis para os times analíticos internos.
Esse é um cenário clássico de multi-cloud, em que diferentes partes da operação utilizam provedores distintos.
A solução foi construir um pipeline de replicação para mover os dados do GCP para a AWS, seguindo o modelo de Passthrough Replicator. O objetivo era simples: garantir que o dado chegasse ao destino exatamente como saía da origem.
Para isso, foram adicionadas etapas de validação ao longo do pipeline, verificando se o volume de dados estava correto e se os registros permaneciam íntegros a cada execução.
Case 2: Compartilhamento de dados com parceiros externos
Em outro projeto, foi necessário compartilhar algumas tabelas com parceiros externos dentro da arquitetura de Data Mesh. O problema é que essas tabelas continham um identificador pessoal (PII), que não podia sair do ambiente corporativo.
A solução foi aplicar o Transformation Replicator. Durante a replicação, o pipeline substituía o atributo PII por um identificador interno anonimizado, atendendo aos requisitos de compliance sem comprometer o uso dos dados pelos times consumidores.
Esse padrão é indicado quando o dado não pode ser replicado como está, geralmente por conter informações sensíveis que não podem circular entre ambientes.
Padrão 2: Particionamento de Dados
O problema
Dados de marketing são naturalmente temporais. Eventos de usuário, impressões de anúncios e conversões têm uma dimensão de tempo intrínseca. Sem uma estratégia de organização, os datasets crescem de forma desestruturada, o que torna consultas mais lentas, reprocessamentos mais caros e pipelines mais difíceis de manter.
O desafio se agrava em fontes como o GA, que permitem atualizações retroativas de até 72 horas após a geração dos eventos. Isso exige uma abordagem que suporte reprocessamentos pontuais sem comprometer o histórico já consolidado.
O padrão
O Particionamento de Dados divide um dataset em partes menores com base em um atributo, com o objetivo de melhorar performance, escalabilidade e organização. O livro apresenta dois tipos complementares.
Particionamento Horizontal
Distribui os registros em diferentes locais de armazenamento com base em uma chave de particionamento. Partições temporais são as mais comuns, pois definem limites de tempo para o processamento e permitem consultar apenas o intervalo de interesse de forma mais rápida e com menor custo. No entanto, chaves de negócio também podem ser usadas, como ID do cliente, região geográfica, país ou ID da campanha.
Veja um exemplo de separação de eventos por data de ocorrência:

Cada partição contém apenas os eventos daquele período. Isso permite reprocessar apenas a partição impactada por eventos atrasados, sem precisar reprocessar todo o histórico já estabilizado.
Além disso, o livro destaca que o particionamento horizontal é um componente importante para garantir a independência. Ao limpar e reescrever uma partição, é possível garantir que um pipeline reprocessado produza sempre o mesmo resultado, desde que os dados de origem não sejam alterados.
Particionamento Vertical
Enquanto o particionamento horizontal divide linhas, o particionamento vertical divide colunas. O livro apresenta esse padrão no contexto de remoção de dados pessoais (LGPD/GDPR), mas ele vai além disso: qualquer dataset em que parte dos atributos é estável e outra parte muda com frequência pode se beneficiar dessa estratégia.
O primeiro passo é identificar quais colunas serão separadas e qual atributo servirá como chave para recompor o registro quando necessário. Em seguida, o pipeline de ingestão é adaptado para gravar cada parte em um local de armazenamento distinto. Veja o exemplo abaixo:
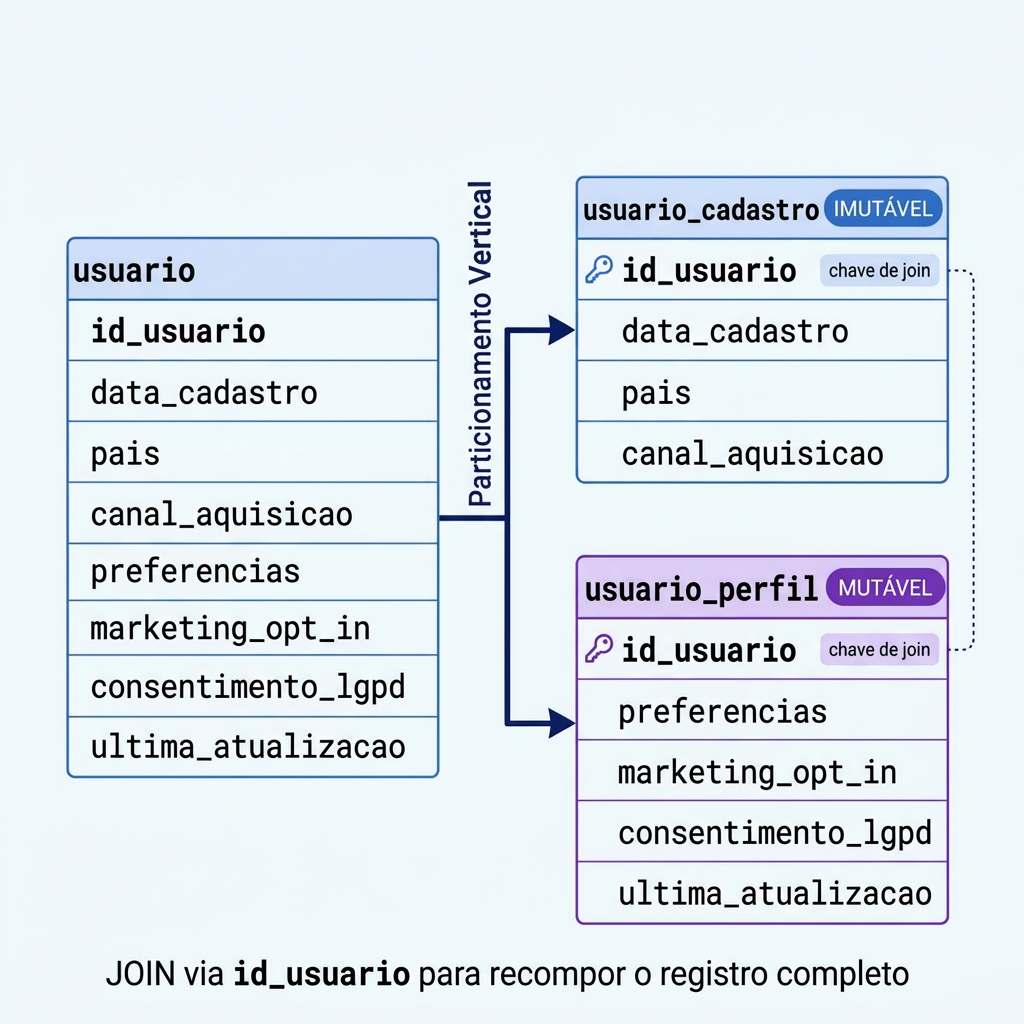
Esse padrão traz um trade-off importante. Ele melhora o desempenho de escrita ao reduzir o volume de dados processados, mas aumenta o custo de leitura, já que passa a ser necessário fazer um join entre as partes. Na prática, isso significa mais processamento e, em muitos casos, mais tráfego de rede. Por isso, é importante avaliar se esse custo é aceitável para o caso de uso.
Em pipelines de marketing, é comum que alguns atributos mudem com frequência enquanto outros permanecem estáveis. O particionamento vertical ajuda a separar essas responsabilidades:
- Dados relativamente estáveis: data de cadastro, origem do usuário, canal de aquisição
- Dados mutáveis: preferências de marketing, consentimento LGPD, segmento de audiência
Os dois tipos de particionamento podem ser combinados. Por exemplo, é possível usar o particionamento vertical para separar dados cadastrais de dados de comportamento e, ao mesmo tempo, aplicar o particionamento horizontal por data em cada uma dessas partes.
Como a DP6 aplica esse padrão no dia a dia?
Em um projeto de CRM, as tabelas do ambiente analítico foram estruturadas combinando os dois tipos de particionamento.
Particionamento vertical:
Foi aplicado para separar os dados cadastrais dos usuários dos dados de interação e comportamento. Essas duas bases tinham frequências de atualização muito diferentes: os dados cadastrais eram atualizados mensalmente, enquanto os dados comportamentais chegavam diariamente.
Ao separar essas responsabilidades, foi possível reduzir o custo de atualização, já que mudanças nos dados de comportamento não exigiam a reescrita dos dados cadastrais, e vice-versa.
Esse benefício não está restrito a cenários com requisitos de LGPD. Sempre que um dataset possui atributos com ciclos de atualização diferentes, o particionamento vertical é uma estratégia eficaz para reduzir I/O e simplificar a manutenção dos pipelines.
Particionamento horizontal:
Foi aplicado nas tabelas de eventos de campanhas derivadas do GA. Como a plataforma permite atualizações retroativas de até 72 horas, as tabelas foram particionadas com granularidade diária (Figura 2). Isso permite reprocessar apenas as partições impactadas por eventos atrasados, sem reprocessar todo o histórico.
Para tabelas consultadas de forma agregada por mês ou ano, a granularidade foi ajustada conforme o uso. Algumas foram particionadas por ano, mês e dia (Figura 4), permitindo diferentes níveis de agregação. Outras foram consolidadas em uma única partição por data (ano-mês-dia), quando as consultas sempre ocorriam nessa granularidade, o que simplificou as queries e reduziu o overhead operacional.

Padrão 3: Deduplicação com Janela
O problema
A duplicação de registros é um problema recorrente em pipelines de marketing. Plataformas externas frequentemente reenviam eventos em caso de falha. Integrações paralelas podem processar os mesmos dados por caminhos diferentes. Além disso, falhas em ferramentas de coleta podem gerar múltiplos disparos para uma única ação do usuário.
Um exemplo comum é uma ferramenta de analytics configurada para registrar um evento de conversão que, por um erro de implementação, envia dois ou três eventos para a mesma ação. Do ponto de vista do pipeline, esses registros chegam como eventos distintos, o que infla métricas e compromete as análises.
O ideal é tratar essas duplicidades na origem, garantindo que cada evento tenha um identificador único ou que a aplicação emissora implemente idempotência. No entanto, em projetos de marketing digital, onde os dados vêm de plataformas externas sem controle direto, isso nem sempre é possível dentro do prazo exigido pelo negócio.
O padrão
O deduplicador de janela (Windowed Deduplicator), descrito no livro, remove duplicatas mantendo apenas uma ocorrência de cada registro dentro de um intervalo de tempo definido. O termo “janela” refere-se ao escopo considerado para a deduplicação. Em jobs batch, esse escopo é o próprio dataset sendo processado. Em streaming, são janelas de tempo explicitamente definidas.
O primeiro passo é definir a chave de unicidade, ou seja, quais atributos identificam unicamente um evento. O livro reforça que essa definição é uma regra de negócio, não apenas técnica, e deve ser documentada de forma explícita. Dependendo do contexto, pode ser:
- event_id (quando disponível na fonte)
- user_id + event_name + event_timestamp
- concatenação de múltiplas colunas, incluindo, em casos extremos, todas as colunas da tabela quando não há uma chave única clara
Uma abordagem inicial comum é o uso de DISTINCT, mas ela tem limitações importantes: remove apenas linhas completamente idênticas. Em cenários reais, registros duplicados frequentemente diferem em metadados de ingestão, como o momento em que o dado chegou ao pipeline:

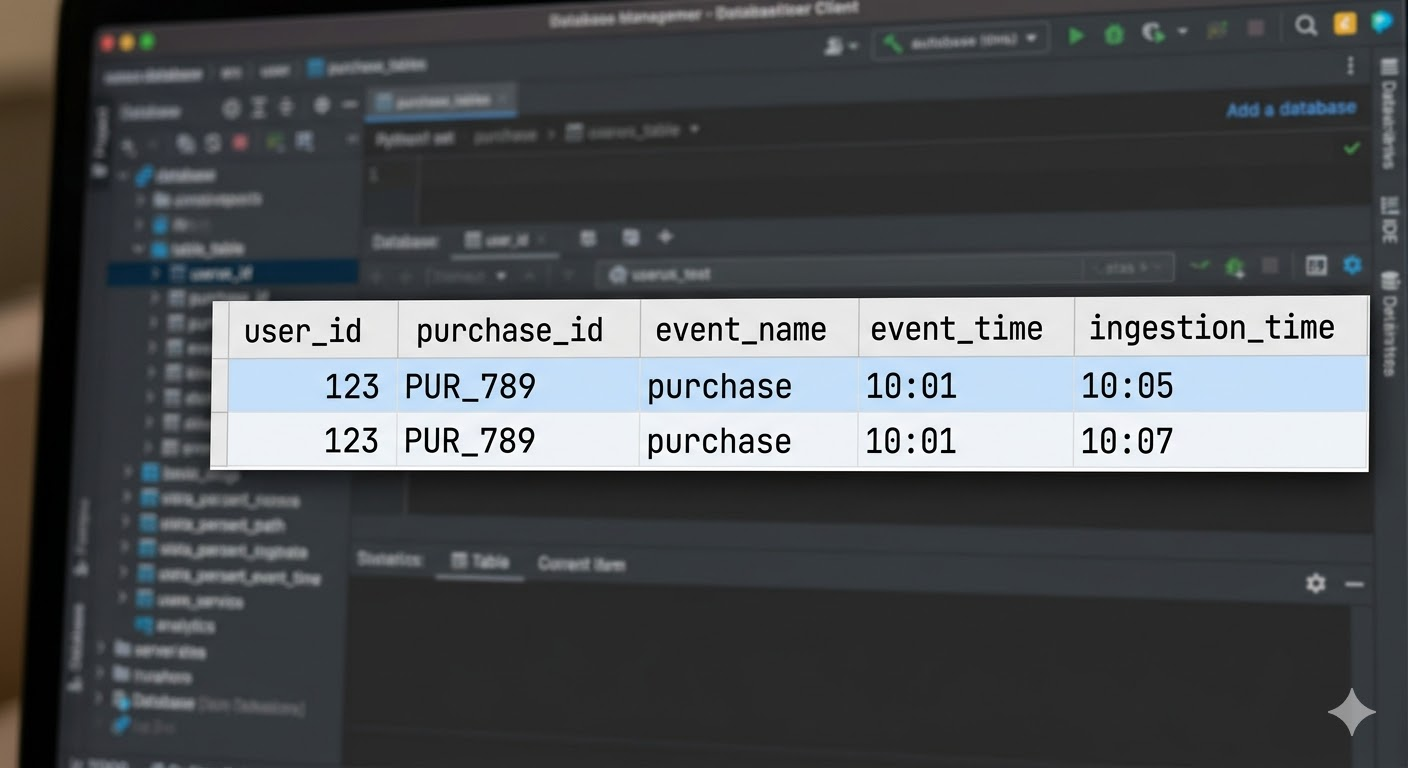
Do ponto de vista do negócio, trata-se do mesmo evento. No entanto, o DISTINCT não os removeria, pois as linhas diferem em ingestion_time. Além disso, o uso de DISTINCT pode ser custoso em datasets grandes, já que exige comparações entre todos os registros.
Uma abordagem mais robusta é utilizar window functions, que permitem definir critérios explícitos para resolver conflitos entre registros duplicados:
SELECT *
FROM (
SELECT *,
ROW_NUMBER() OVER (
PARTITION BY purchase_id -- A chave de unicidade é o ID da compra
ORDER BY ingestion_time DESC -- Mantém o registro mais recente
) AS row_num
FROM events
)
WHERE row_num = 1
Nesse exemplo, quando dois registros representam o mesmo evento, o mais recente com base em ingestion_time é mantido. Isso é especialmente útil quando eventos chegam com pequenas diferenças entre versões do mesmo dado.
Manter uma coluna de ingestion_time nas tabelas analíticas é uma boa prática complementar. Ela é essencial para aplicar esse tipo de lógica, além de facilitar análises de qualidade, rastreabilidade de reprocessamentos e identificação de duplicidades inesperadas.
Como a DP6 aplica esse padrão no dia a dia?
Em um projeto para uma plataforma de streaming e entretenimento, o pipeline precisava processar dados de comportamento do usuário, como cliques, visualizações e interações, para alimentar um modelo de recomendação de ofertas personalizadas.
Os eventos chegavam por meio de uma ferramenta interna de monitoramento da jornada do usuário. Por ser uma solução relativamente nova no cliente, a tabela bruta apresentava duplicidades com frequência. O mesmo evento de interação aparecia múltiplas vezes, com pequenas variações em campos de metadados de ingestão.
A solução foi aplicar ROW_NUMBER(), particionando os dados pela combinação de atributos que identificavam unicamente cada interação. Como a tabela era processada no nível de usuário, o critério de unicidade combinava o identificador do usuário com os atributos do evento.
O registro mais recente com base em ingestion_time era mantido, e os demais eram descartados antes da carga nas tabelas analíticas utilizadas pelo modelo de recomendação. Isso garantiu que o modelo fosse treinado com dados limpos e representativos, evitando inflar artificialmente o peso de determinadas interações.
Padrão 4: Detector de Dados Atrasados
O problema
Diferentes fontes de marketing produzem dados em ritmos distintos. Dados de Google Ads chegam quase em tempo real. Eventos do GA podem ter atraso de até 72 horas. Conversões offline ou dados de CRM podem levar dias para aparecer.
Se o pipeline aguarda que todas as fontes estejam completas antes de produzir resultados, os produtos de dados, como dashboards, podem ficar desatualizados e pouco úteis. Por outro lado, se o pipeline avança sem considerar esses atrasos, as métricas são calculadas de forma incompleta, gerando inconsistências que confundem stakeholders e comprometem na tomada de decisões.
O padrão
O detector de dados atrasados (Late Data Detector) e suas variações resolvem esse problema ao definir explicitamente até que ponto no tempo os dados são considerados suficientemente completos para processamento.
O conceito central é o watermark: uma referência no tempo calculada como MAX(event_time) - allowed_lateness, onde allowed_lateness é o atraso máximo tolerado. Qualquer evento com timestamp anterior ao watermark atual é considerado atrasado.
Existe uma nuance importante ao calcular o watermark em sistemas com múltiplas fontes ou partições. Para garantir que o pipeline avance de forma monotônica, sem “voltar no tempo”, a estratégia de agregação do event_time precisa ser bem definida:
- Uso de MIN entre as fontes: segue a fonte mais lenta, garantindo completude, mas podendo aumentar o volume de dados em espera
- Uso de MAX entre as fontes: segue a fonte mais rápida, reduzindo o volume em buffer, mas com risco de ignorar dados de fontes mais lentas
- Combinação de MIN/MAX: cada fonte aplica MAX internamente, e o watermark global usa MIN entre fontes
Embora o conceito de watermark seja mais comum em streaming, ele também se aplica a pipelines batch. Nesses casos, o problema deixa de ser detectar latência em tempo real e passa a ser definir por quanto tempo o pipeline continuará aceitando dados atrasados para uma determinada janela temporal.
Estratégias em pipelines batch
Na prática, algumas estratégias são mais comuns:
- Janela fixa de atraso: define um período máximo de tolerância, como 72 horas para dados do GA, e reprocessa apenas esse intervalo ao receber dados retroativos. É a abordagem mais simples.
- Publicação em camadas (atualização incremental): publica resultados preliminares assim que os dados chegam e os atualiza progressivamente conforme dados atrasados são incorporados. Um fluxo típico pode ser:
D+0 → processamento inicial com os dados disponíveis
D+1 → atualização com eventos atrasados
D+2 → nova atualização
D+3 → fechamento da janela, com dados considerados estáveis - Observação de estabilização: monitora quando as métricas deixam de variar de forma relevante e ajusta dinamicamente a janela de atraso. É útil quando o comportamento das fontes muda ao longo do tempo.
- Uso de metadados da fonte: algumas plataformas fornecem sinais explícitos de progresso, como timestamps de processamento, versões de dataset ou indicadores de finalização. Quando disponíveis, são os sinais mais confiáveis para determinar quando os dados estão completos.
Quando esses sinais não existem, uma abordagem prática é validar o volume de dados. O pipeline compara o volume recebido com o histórico esperado para aquele período e sinaliza possíveis inconsistências quando há desvios relevantes.
Como a DP6 aplica esse padrão no dia a dia?
Em um projeto de atribuição multicanal para um cliente com operações físicas e digitais, o pipeline precisava integrar dados de interação e conversão de mais de 10 canais distintos. O principal desafio era que nem todas as fontes disponibilizavam dados no mesmo momento em que o pipeline executava, o que exigia uma estratégia clara para lidar com diferentes janelas de atualização.
A abordagem adotada foi estruturar o pipeline em duas camadas. A primeira processava diariamente os dados já disponíveis, publicando resultados preliminares para consumo imediato. A segunda operava com uma janela de atraso de 72 horas, incorporando as fontes mais lentas, como dados de conversão física provenientes do CRM, e corrigindo as métricas de atribuição com valores consolidados.
Uma das origens mais críticas era o Google Analytics. Por padrão, o GA exporta os dados de eventos para o BigQuery em dois formatos: a tabela events_intraday_YYYYMMDD, que é atualizada ao longo do dia com eventos ainda em processamento, e a tabela events_YYYYMMDD, consolidada ao final do dia com os eventos processados. Esse processo pode levar até 72 horas após o início do dia, o que significa que dados de D-1 podem não estar completos quando o pipeline executa pela manhã.
Sem um SLA claro para a disponibilidade dos dados consolidados de D-1, foi necessário adotar uma abordagem híbrida. O pipeline consumia os dados da tabela intraday enquanto a tabela consolidada não estava disponível. Assim que a tabela final passava a ter dados completos, a origem era automaticamente substituída. Isso permitia publicar resultados preliminares rapidamente, sem esperar pela consolidação total.
Outro desafio foi a ausência de notificações explícitas das fontes indicando atrasos ou necessidade de reprocessamento. Sem esse tipo de sinal, a solução adotada foi a validação de volume. O pipeline comparava o volume recebido com o histórico esperado para o período e, em caso de desvios relevantes, acionava uma investigação para que o time verificasse os dados de origem e, em alguns casos, o reprocessamento correspondente no pipeline de destino.
Conclusão
Os quatro padrões apresentados neste artigo (Replicador de Dados, Particionamento, Deduplicação com Janela e Detector de Dados Atrasados) não são soluções exclusivas do marketing digital. Mas aparecem com frequência especialmente nesse contexto, pela dependência estrutural de fontes externas com comportamentos distintos de atualização, latência e confiabilidade.
Cada padrão resolve um problema específico. O Replicador de Dados permite centralizar dados de fontes externas sem depender delas durante as análises. O Particionamento organiza datasets temporais, viabilizando consultas mais eficientes e reprocessamentos pontuais. A Deduplicação com Janela evita que métricas sejam infladas por eventos duplicados. Já o Detector de Dados Atrasados permite que pipelines publiquem resultados de forma progressiva, sem precisar esperar que todas as fontes estejam completas.
O valor desses padrões não está apenas na solução técnica, mas também na linguagem compartilhada que eles criam. Quando um time consegue nomear o problema que está enfrentando, fica mais fácil discutir trade-offs, documentar decisões e reaplicar soluções em outros contextos.
Para quem quiser se aprofundar, o livro Data Engineering Design Patterns, de Bartosz Konieczny (O'Reilly, 2025), é uma referência completa. A obra cobre desde ingestão e transformação até qualidade e observabilidade de dados, sempre apresentando cada padrão a partir do problema, das alternativas e das implicações práticas em cenários reais.
Se a sua empresa está enfrentando desafios para estruturar pipelines confiáveis, integrar múltiplas fontes de dados ou escalar sua arquitetura analítica, a DP6 pode ajudar. Somos especialistas em engenharia de dados aplicada ao marketing, com experiência prática na construção de soluções robustas, eficientes e orientadas a resultados. Entre em contato com a gente e descubra como transformar seus dados em vantagem competitiva real.

Descubra o que rolou no 7º Data Analytics & AI Community Brazil e por que o verdadeiro gargalo da IA é a cultura de dados.

Descubra como um agente inteligente de IA generativa revolucionou a gestão comercial de um grande grupo de mídia.

Sua empresa decide pelo placar ou pela tendência? Entenda como o mau uso da estatística gera decisões erradas, usando a Copa de 2026 como exemplo.
