Atribuição Multicanal: Otimizando investimento em mídia online com Data Science

Hoje vamos falar sobre Atribuição Multicanal (Multitouch attribution).
O post de hoje é diferente de tudo que você já viu, pois vamos apresentar a biblioteca em Python criada pelos nossos cientistas de dados chamada Marketing Attribution Models, ou simplesmente MAM para os íntimos.
Só para relembrar em uma frase o que é atribuição multicanal e o problema que ele resolve, podemos dizer que trata-se de um método que objetiva estimar o quanto cada canal contribuiu para a conversão e não apenas enxergar o último canal de contato com o cliente, calculando algoritmicamente a contribuição fracional de cada canal avaliando todas as jornadas de clientes capturadas pelas ferramentas de digital analytics e mídia, possibilitando uma otimização de investimento mais realista e um entendimento mais completo da jornada.
Neste primeiro post, iremos abordar os modelos heurísticos implementados na nossa biblioteca MAM e, posteriormente, os modelos algorítmicos, por isso não perca os próximos capítulos.
Modelos Heurísticos
Nos capítulos anteriores, vimos que os modelos heurísticos (ou Rule-Based) são tipos de atribuição pré-definidas, isto é, baseadas em regras fixas.

Essas regras são adotadas, geralmente, a partir do entendimento do modelo de negócio e particularidades de campanhas.
Pontos positivos
- Implementação rápida e fácil, geralmente já configurados por padrão nas ferramentas de Analytics;
- Alta interpretabilidade e baixo custo.
Pontos negativos
- Baixa previsibilidade, por não ser baseados em dados e sim em regras, caso ocorra alguma alteração de objetivos e campanhas, o modelo continuará a seguir a regra estabelecida;
- Abordagem subjetiva, geralmente não contempla a jornada como um todo e sim pontos de contato isolados.
Pulemos agora para a parte mais divertida: codar!
Então apertem os cintos e pip install marketing-attribution-models.
Instalando e importando a biblioteca
```
>>> pip install marketing_attribution_models
>>> from marketing_attribution_models import MAM
```Se você não tem um dataset para treinar, não se preocupe, nós cuidamos disso para você!
Implementamos uma forma de gerar uma base de dados aleatória através do parâmetro random_df=True.
Caso você queira usar a biblioteca com seus próprios dados, utilizando todos os parâmetros disponíveis, temos um tutorial bem detalhado no nosso github.
Criando o objeto MAM
Após o importar a biblioteca, podemos criar um objeto MAM e nele chamar nele os métodos de atribuição disponíveis na classe.
```
>>> attributions + MAM (random_df-True)
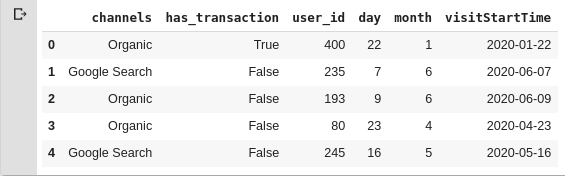
```Visualizando o dataframe
Como passamos o parâmetro random_df=True, internamente é criado um dataframe randômico.
Para visualizar esse dataframe, chamamos o atributo .original_df no objeto MAM.
A função head() vem do Pandas e por padrão exibe só as 5 primeiras linhas do dataframe.
```
>>> attributions.original_df.head()
```Output:
Modelos Heurísticos
Last-Click
O último canal antes da conversão recebe todo o crédito.
Modelo padrão das principais ferramentas de compra de mídia e de Digital Analytics.
```
>>> last_click = attributions.attribution_last_click()‘’O método .attribution_last_click() retorna uma tupla, na qual as conversões atribuídas a cada canal está no elemento de índice 1.
>>> last_click[1]
```Output:

First-Click
O canal do início da jornada (online) é quem recebe 100% do crédito da conversão.
Com ele é possível atribuir aos canais que iniciam o processo de decisão do consumidor.
```
>>> first_click = attributions.attribution_first_click()
>>> first_click[1]
```Output:

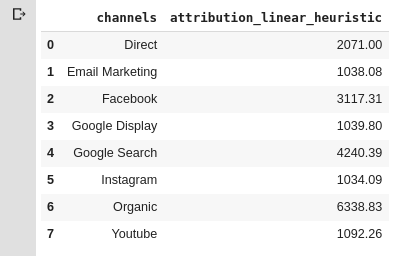
Linear
O crédito da conversão é distribuído igualmente para todos os canais.
Nesse caso, cada ponto de contato é igualmente importante durante o processo de consideração.
```
>>> linear = attributions.linear()
>>> linear[1]
```Output:
Position Based
Por padrão, inclusive nas ferramentas de Analytics, o primeiro e o último canal são priorizados com 40%, distribuindo o restante linearmente para os outros pontos de contato, por isso é chamado também de U-Shaped.
No entanto, aqui esse modelo pode ser customizado pelo parâmetro list_positions_first_middle_last=[0.4, 0.2, 0.4], onde passamos as porcentagens que queremos atribuir a cada posição.
```
>>> position_based = attributions.attribution_position_based()
>>> position_based[1]
```Output:

Time Decay
Os créditos são atribuídos progressivamente aos canais que estão mais próximos da conversão de acordo com a distância em dias da interação.
Esse modelo pode ser customizado quanto ao percentual de decaimento no parâmetro decay_over_time e quanto ao tempo em horas na qual esse percentual será aplicado no parâmetro frequency.
Abaixo estão ilustrados os valores padrão: decaimento de 50% a cada 7 dias.
```
>>> time_decay = attributions.time_decay(decay_over_time=0.5,
frequency=168
>>> time_decay[1]
```Output:

Last Click Non-X
Todo o tráfego de um canal específico é substituído pelo canal antecedido a ele e 100% do crédito da venda vai para o último canal pelo qual o cliente entrou antes de converter.
Criamos esse modelo para replicar o comportamento padrão do Google Analytics no qual o tráfego Direto é sobreposto caso seja antecedido por uma interação de outra origem dentro de determinado período.
Por exemplo, temos a seguinte jornada na qual usaremos a atribuição Last Click Non-Direct: Facebook > Direto.
Após a sobrescrição do Direto, teremos como resultado a jornada Facebook > Facebook e as conversão serão atribuídas 100% ao Facebook.
Nesse método, podemos passar o canal X que desejamos sobrescrever no parâmetro but_not_this_channel.
No exemplo abaixo, vamos fazer a sobrescrição do tráfego Direto.
```
>>> non_direct =
attributions.attribution_last_click_non(but_not_this_channer='Direct')
>>non_direct[1]
```Output:

Você pode estar se perguntando: mas tenho que rodar um de cada vez? E se eu quiser visualizar todos eles juntos?
Tudo de uma vez: todos heurísticos
Caso você queira uma rodar todos os heurísticos de uma vez, nós também facilitamos a vida pra você!
```
>>> attributions.attribution_all_models(model_type="heuristic')
```Além disso, temos um atributo na classe que salva os modelos que você vai rodando ao longo do código em um único dataframe.
```
>>> attributions.group_by_channels_models
```Atenção: Os resultados agrupados não se sobrescrevem caso o mesmo modelo seja calculado mais de uma vez e ambos resultados estarão presentes no atributo group_by_channels_models.
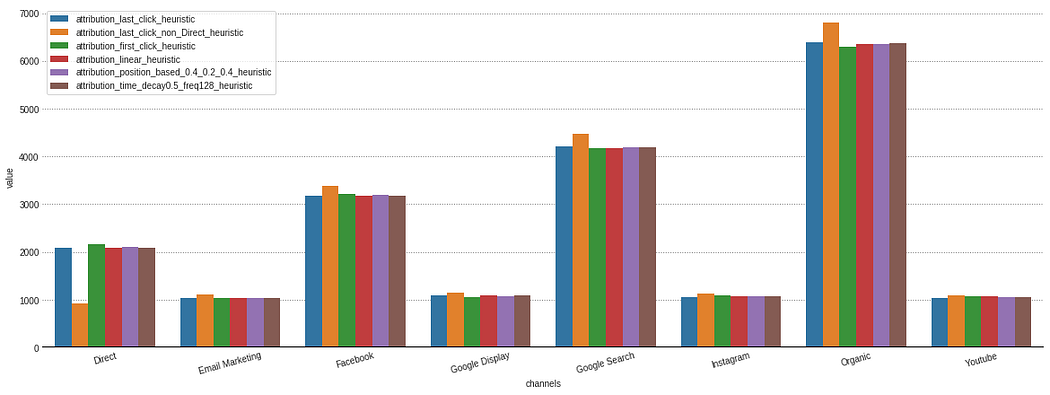
Visualização
Para a visualização dos resultados, implementamos o método attributions.plot()
```
>>> attributions.plot(model_type='heuristic')
```Output
Resumindo
Em 5 linhas:
```
>>> pip install marketing_attribution_models
>>> from marketing_attribution_models import MAM
>>> attribution = MAM(random_df=True)
>>> attribution.attribution_all_models(model_type='heuristic')
>>> attributions.plot(model_type='heuristic')
```Lembrando que já temos um guia bem explicativo no README do repositório de como funcionam esses modelos e como foram implementados. Não deixe de conferir!
Agora vamos abordar os modelos algorítmicos. Estes implementados na nossa biblioteca MAM.
O que são modelos algorítmicos?
São modelos de atribuição baseados em algoritmos e não somente em regras.
Na prática isso significa que, em vez de aplicar uma regra que será usada de forma estática para todos os possíveis caminhos de conversão, como nos modelos heurísticos, a atribuição será feita com base nos próprios caminhos de conversão. Ou seja, a atribuição é baseada em dados.
Por que usá-los?
Tomemos como exemplo a jornada da Stacy.
Ela passou por 900 pontos de contatos digitais no período de 3 meses durante o processo de decisão da compra de um carro.

Nesse cenário, seria justo atribuir a conversão somente ao último ponto de contato? Ou somente ao primeiro?
Até mesmo pensando em uma atribuição multi-touch linear, será que todos os pontos participaram igualmente da jornada ou alguns canais apareceram mais do que outros?
É isso que os modelos algorítmicos nos respondem baseado em dados.
Quando pensar além do single-touch?
Em casos como o da Stacy, modelos heurísticos de um único ponto como o Last Click deixam de ser suficientes e passam a reportar uma visão incompleta da jornada.
É preciso ir além do single-touch quando:
- A maior parte das suas conversões acontece a partir de mais de 1 visita, tal que o tamanho da jornada do seu produto envolve mais de 1 ponto de contato;
- As conversões na sua propriedade digital não acontecem normalmente no primeiro dia;
- Sua empresa investe um volume relevante em mídia digital em diferentes fontes e formatos de anúncio.
O mais indicado nesses casos é partir para modelos de atribuição que levem em consideração a jornada como um todo, como os modelos algorítmicos.
Vamos aqui apresentar dois deles: Shapley Value e as Cadeias de Markov.
Shapley Value
“Como associar diferentes agentes da melhor forma possível?”
A resposta a essa pergunta foi baseada na Teoria dos Jogos e Prêmio Nobel de Economia em 2012 para Lloyd Shapley.
Imaginemos um jogo de cooperação, ilustrado na figura abaixo:
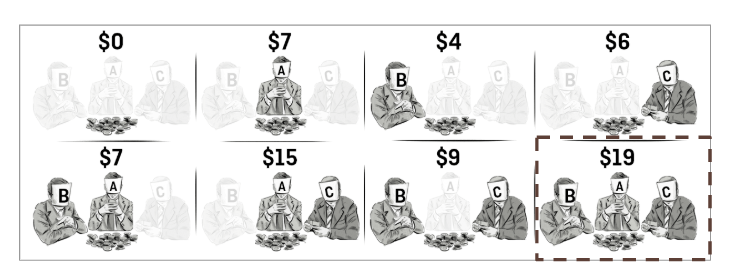
Como atribuir a contribuição dos jogadores A, B e C no resultado de $19?
Calculando o Shapley Value de cada jogador.
No contexto de Marketing Digital, cada canal da jornada tem o papel de um jogador, tal que o jogo de cooperação tem como objetivo a conversão.
O Shapley Value atribui os créditos das conversões calculando a contribuição de cada canal presente na jornada, utilizando permutações de jornadas com e sem o canal em questão.
Calculado com base em observações: para cada jornada, é preciso ter o valores de
conversão para todas as combinações que a compõe.
Como assim? Eu explico!
Para saber a contribuição de cada canal na jornada abaixo precisamos de todas as jornadas seguintes.

Por exemplo:
A contribuição do Facebook é calculada a partir das seguintes permutações:

Traduzindo:
- Quantas conversões o Facebook sozinho trouxe?
- Quantas conversões a jornada Facebook > Direto trouxe subtraindo as conversões do Direto sozinho?
- Quantas conversões a jornada Facebook > Natural trouxe subtraindo as conversões do Natural Search sozinho?
- Quantas conversões a jornada Natural > Facebook > Direto trouxe subtraindo as conversões da jornada Natural > Direto?
Por fim, as conversões atribuídas ao Facebook será uma média ponderada das contribuições calculadas anteriormente.

Fórmula matemática do Shapley Value para os nerds (eu mesma).
Considerando a ordem dos canais, a quantidade de dados necessários e o número de iterações passa a ser muito maior (da ordem de 2^n, sendo n o número de canais), pois agora precisamos de todas as permutações possíveis, caso contrário será atribuído um valor nulo àquela jornada.
O Google Data-Driven Attribution utiliza o Shapley Value e limita as jornadas em 4 pontos de contato, por conta desse problema de escalabilidade próprio do algoritmo.
Vamos agora introduzir um outro modelo que lida melhor com esse problema.
Cadeias de Markov
Em “tecniquês”, uma cadeia de Markov representa qualquer evento que varia de forma aleatória através do tempo, tal que a probabilidade de mudança para um estado futuro depende apenas do estado atual.
Traduzindo: a probabilidade de chover amanhã independe de ter chovido ontem, mas apenas do tempo de hoje.
No contexto de Marketing Digital, podemos modelar a jornada do usuário como uma Cadeia de Markov, onde os estados são representados pelos canais e a transição representa a interação do usuário partindo de um canal para outro.
As interações do usuário podem ser representadas na forma de grafos ou na chamada de Matriz de Transição.


Com a matriz de transição conseguimos visualizar a probabilidade de interação entre canais e assim conseguimos buscar combinações de canais com maiores chances de levar a conversão.
Como assim? Eu explico!
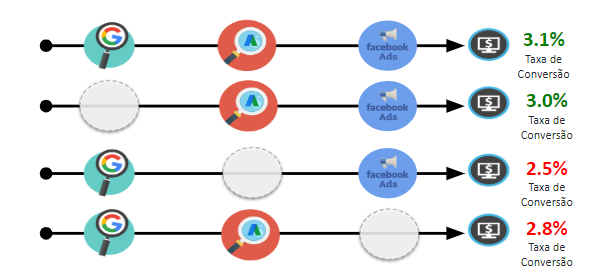
Na matriz ilustrada acima, Google Ads tem maior probabilidade de conversão, então podemos ver na matriz quais canais são mais prováveis de levar o usuário para Ads.
O canal com maior probabilidade de transição para Ads é o Facebook.
Portanto, a jornada Facebook > Ads pode ser um bom caminho para a conversão.
E como são atribuídas as conversões de cada canal?
A contribuição de cada canal na conversão é calculada pelo Removal Effect.
Remove-se este da jornada e calcula-se a probabilidade de conversão sem ele, assim conseguimos mensurar o seu “peso” na conversão.

Descubra como um agente inteligente de IA generativa revolucionou a gestão comercial de um grande grupo de mídia.

Sua empresa decide pelo placar ou pela tendência? Entenda como o mau uso da estatística gera decisões erradas, usando a Copa de 2026 como exemplo.

Descubra os principais insights do Cannes Lions 2026, o maior festival de criatividade do mundo!
